Neat Info About What Is OCR In Python

Unlocking Text from Images
1. What's the Big Deal with OCR?
Ever found yourself staring at an image containing text, wishing you could just copy and paste it? Or maybe you needed to automatically process scanned documents? That's where Optical Character Recognition, or OCR, comes to the rescue. Think of it as a magical translator that converts images of text into actual, editable text. It's like teaching your computer to "read."
And why Python, you might ask? Well, Python's known for its simplicity, readability, and a treasure trove of libraries that make complex tasks manageable. It's the perfect language for tackling OCR, even if you're not a coding wizard.
Imagine you have a stack of old receipts you want to digitize for expense tracking. Doing it manually would be a total drag, right? With OCR in Python, you can automate the entire process, extracting the relevant information and saving yourself precious time and energy. It's all about working smarter, not harder!
From automating data entry to making scanned documents searchable, the possibilities are endless. Seriously, once you get a taste of what OCR can do, you'll start seeing opportunities for it everywhere. Okay, maybe not everywhere, but you get the idea. It's a powerful tool to have in your programming arsenal.
2. Python and OCR
So, how do we actually do OCR in Python? The secret lies in powerful libraries like Tesseract OCR and pytesseract, which acts as a Python wrapper for Tesseract. Tesseract is like the engine that does the heavy lifting of the character recognition, while pytesseract makes it easy to interact with that engine from your Python code. It's a team effort!
Setting it up can seem a little daunting at first, involving installing Tesseract separately and then installing pytesseract using pip (Python's package installer). But don't worry, there are plenty of tutorials and guides out there to walk you through the process, step-by-step. Think of it as assembling a Lego set — a slightly complex Lego set, maybe, but still manageable.
Once you have everything installed, you can start feeding images to pytesseract and watch it magically extract the text. You can even tweak parameters to improve accuracy, like specifying the language of the text or adjusting image preprocessing techniques. It's all about fine-tuning the engine to get the best possible results.
Remember, OCR isn't perfect. Handwriting can be tricky, and poor image quality can throw things off. But with a little experimentation and some clever preprocessing, you can achieve impressive accuracy in many cases. Just don't expect it to decipher your doctor's scribbles — even the best OCR systems have their limits.
Getting Your Hands Dirty
3. Let's See Some Code!
Alright, let's dive into a basic code example to illustrate how easy it is to use OCR in Python. First, you'll need an image with some text. Save it as something like "image.png". Then, you can use the following code snippet:
from PIL import Imageimport pytesseract# Path to the Tesseract executable (replace with your actual path)pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'# Open the image using Pillowimg = Image.open('image.png')# Perform OCR using pytesseracttext = pytesseract.image_to_string(img)# Print the extracted textprint(text)Make sure you replace the `tesseract_cmd` path with the actual location of the Tesseract executable on your system. Also, you might need to install Pillow (PIL) using `pip install Pillow`. This code opens the image, feeds it to pytesseract, and then prints the extracted text. Simple as that!
Now, run this code and see what happens. If everything is set up correctly, you should see the text from your image printed in the console. Of course, the accuracy will depend on the quality of the image and the complexity of the text. But this is a great starting point for experimenting with OCR in Python.
This is just the beginning! You can build upon this basic example to create more sophisticated OCR applications. Imagine building a program that automatically extracts data from invoices, or a tool that translates text from images in different languages. The possibilities are truly exciting.

Tesseract Ocr In Python With Pytesseract Opencv Vrogue
Beyond the Basics
4. Tips and Tricks for Better Results
Okay, so you've got the basic OCR process working. But what if the results aren't as accurate as you'd like? Don't despair! There are several techniques you can use to improve OCR accuracy. One important step is image preprocessing. This involves cleaning up the image to make it easier for Tesseract to recognize the characters.
Common image preprocessing techniques include converting the image to grayscale, applying thresholding to create a binary image (black and white), and removing noise using filters. These steps can significantly improve the contrast and clarity of the text, making it easier for Tesseract to identify the characters accurately.
Another trick is to adjust the Tesseract configuration. You can specify the language of the text, the page segmentation mode, and other parameters to optimize the OCR process for specific types of documents. Experimenting with these settings can often yield surprising improvements in accuracy.
Finally, consider using specialized OCR engines for specific types of documents. Some OCR engines are specifically designed for recognizing handwritten text, while others are optimized for reading scanned documents or images of text in different languages. Choosing the right engine for the job can make a big difference.
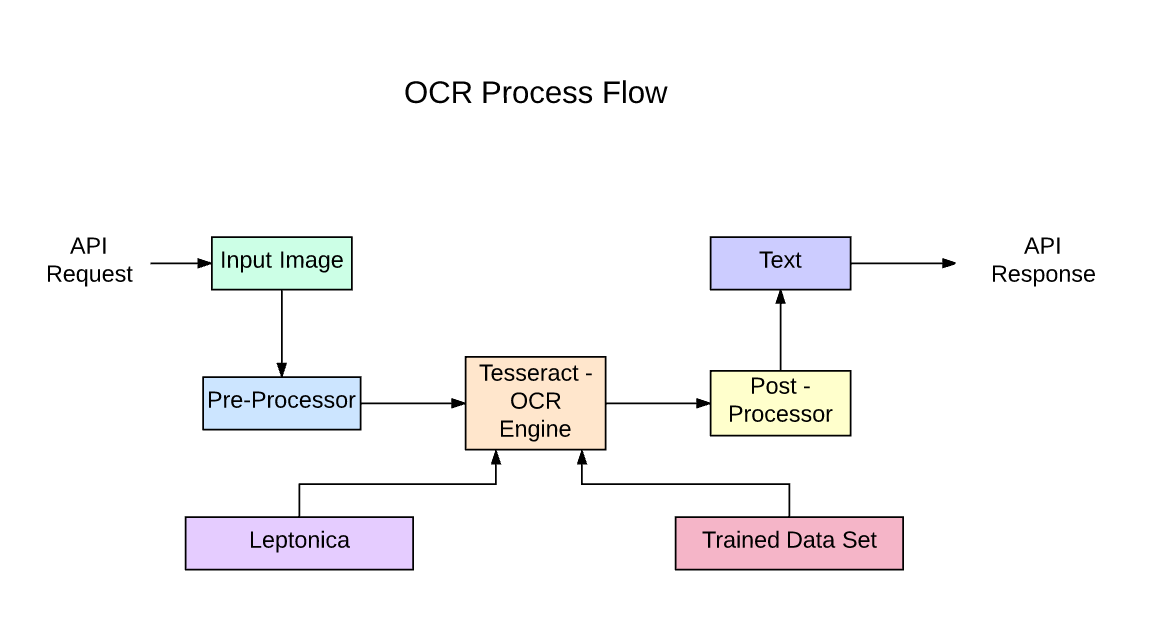
Real-World Applications of OCR in Python
5. Where Can You Use This Magic?
So, now you know what OCR in Python is and how to use it. But where can you actually apply this knowledge in the real world? The possibilities are vast and varied! One common application is in document management. You can use OCR to automatically extract data from scanned documents, such as invoices, receipts, and contracts.
This can save you countless hours of manual data entry and improve the accuracy of your record-keeping. Imagine automatically extracting all the relevant information from hundreds of invoices and storing it in a database. That's the power of OCR!
Another exciting application is in accessibility. You can use OCR to convert images of text into spoken words, making them accessible to people with visual impairments. This can open up a whole new world of information and opportunities for those who rely on assistive technology.
From automating data entry to improving accessibility, OCR in Python has the potential to transform the way we interact with information. It's a powerful tool that can save time, improve accuracy, and unlock new possibilities. So, get out there and start experimenting with OCR — you might be surprised at what you can achieve!

Data Extraction From Pdf Using Python Ocr By Sevendesign78 Fiverr
")